在医疗这个行当里,一个靠谱的医生和一台冰冷的机器,最大的区别是什么?答案或许不是知识储备的多寡,而是一种犹豫。
一位有着北大医学部背景的医生曾坦言,在临床面对拿不准的指标时,绝不会立刻下结论。那种战术性停顿——翻指南、查文献,甚至跑去敲主任办公室的门,恰恰是对生命负责的表现。反观过去的许多医疗AI,它们更像一个急于表现的学生,无论懂不懂,张嘴就来。这种自信放在普通聊天场景中或许无伤大雅,但在性命攸关的诊疗室里,却是致命的缺陷。
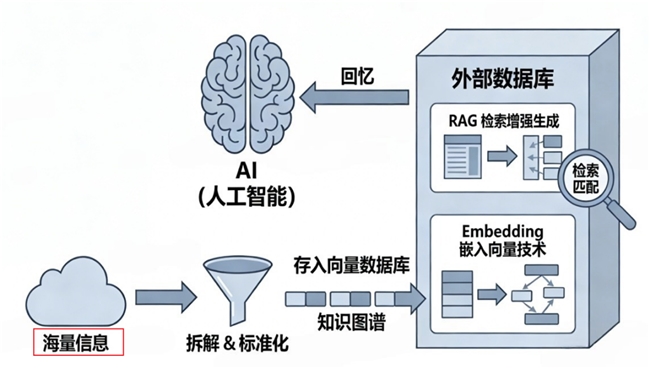
正是洞察到这一痛点,杭州智诊科技有限公司推出了WiseResearch医疗端到端智能体。它试图完成一场深刻的角色转变:将AI从那个不懂装懂的答题机器,进化为一位像资深医生一样会思考、会查证、会犹豫的医疗侦探。
WiseResearch的颠覆性,在于它不再是一个孤立的对话模型,而是一套完整的专家工作流调度引擎。它之所以被内部称为AI医疗界的哆啦A梦,是因为它不再两手空空地靠猜来回答问题,而是拥有一个装满神奇工具的口袋。当遇到一个复杂问题时,它不会急着给答案,而是会像医生那样,先在大脑里进行多轮拆解与规划:这个症状有没有危险信号?需要参考哪些最新文献?该调用哪个工具来辅助诊断?把大问题拆解成一系列可执行的小任务后,它才开始行动。
这套口袋里的工具,每一个都针对医疗场景进行了深度打磨。第一个是名为MedOCR的医学信息抽取智能体。医疗单据的复杂性远超想象:带有上下箭头的生化报告、满是勾选框的体检问卷,这些对于通用OCR模型来说简直是噩梦。市面上主流模型在面对这些特殊符号时,往往出现灾难性错误:代表指标异常的箭头要么漏掉、要么方向标反;患者明明勾选了电磁辐射,模型却把勾选框识别到了无上。这种有和无的颠倒,在医疗领域意味着诊断方向的南辕北辙。而MedOCR凭借针对性的训练优化,在这一细分赛道上达到了行业顶尖水平,能够实现对结构化数据的零失误还原,完美保留每一个符号背后的医学含义。
第二个工具是智诊医学知识库MedDB。传统知识库往往只是数据的简单堆砌,量大而杂乱,分不清哪些是十年前的过时理论,哪些是最新的临床指南。MedDB则像一个经过专家严格审核的图书馆,收录了超过40万条条目,覆盖1.2万种疾病,每条知识都标注了证据等级和时效性。它为大模型提供了一个绝对可信的校验基准,确保AI的每一句话都没有偏离当下的医学共识。
第三个工具是专业医学搜索引擎MedSearch。临床医学日新月异,新药、新共识每天都在涌现。当需要查询多发性骨髓瘤最新指南时,普通搜索引擎可能返回一堆非官方的过时解读,而MedSearch凭借严格的权威优先、时效优先策略,能直接检索到NCCN 2026年最新版以及国内最新发布的权威指南,让模型的建议与国际国内双重标准保持同步。
有了这些工具,WiseResearch的思考过程更像一位严谨的医学生。面对一张包含了免疫球蛋白、甲状腺激素、尿常规等多项指标的复杂混合化验单,它首先调用MedOCR精准提取数据。当发现甲状腺球蛋白抗体异常升高、血清轻链比值偏低时,它没有草率下结论,而是像侦探发现了疑点,针对性地多次调用MedDB和MedSearch进行循序渐进的检索与反复校验。如果证据不够确诊,它绝不会硬猜,而是继续发起多轮调度,直到手里的证据链完整了,才会停止。最终,它给出的不是一句简单的判断,而是一份具备强可解释性的循证结论:明确指出这是自身免疫性甲状腺炎但目前功能正常,无需吃药只需复查;对于危险性较高的轻链异常,也安抚患者无需过度惊慌,并在每一条关键建议后面,都附上了刚刚查到的指南出处。
这种能力的提升最终反映在了冰冷的数字上。在智能诊所医学问答AgentClinic-MedQA榜单上,人类医生的平均分为54.0,而WiseResearch拿下了64.8分,高出整整10分。这10分的差距,并非赢在知识的广度,而是赢在绝对理性的执行力。人类医生在疲劳或过度自信时可能会依赖经验直觉,跳过核对步骤,但WiseResearch不论面对第1个还是第100个病人,都会严格执行检索-核对-校验的标准动作。
从只会聊天的模型,到能跑完整医疗任务流程的智能体,WiseResearch的诞生标志着医疗AI进入了一个新的分水岭。它证明了一件事:在医疗这个关乎生命的领域,AI的价值不在于回答得多快,而在于思考得多深。它不再是一个冷冰冰的机器,而正在成为患者身边那个会查书、会核对、值得信赖的哆啦A梦。